AI, ML, DL
[MediaPipe] Hand Landmark Detection 손 특징 감지
J-sean
2025. 2. 11. 19:28
반응형
MediaPipe를 이용해 손 특징을 감지해 보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
import numpy as np
import cv2
import mediapipe as mp
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
MARGIN = 10 # pixels
FONT_SIZE = 1
FONT_THICKNESS = 1
HANDEDNESS_TEXT_COLOR = (88, 205, 54) # vibrant green
def draw_landmarks_on_image(rgb_image, detection_result):
hand_landmarks_list = detection_result.hand_landmarks
handedness_list = detection_result.handedness
annotated_image = np.copy(rgb_image)
# Loop through the detected hands to visualize.
for idx in range(len(hand_landmarks_list)):
hand_landmarks = hand_landmarks_list[idx]
handedness = handedness_list[idx]
# Draw the hand landmarks.
hand_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
hand_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in hand_landmarks
])
solutions.drawing_utils.draw_landmarks(
annotated_image,
hand_landmarks_proto,
solutions.hands.HAND_CONNECTIONS,
solutions.drawing_styles.get_default_hand_landmarks_style(),
solutions.drawing_styles.get_default_hand_connections_style())
# Get the top left corner of the detected hand's bounding box.
height, width, _ = annotated_image.shape
x_coordinates = [landmark.x for landmark in hand_landmarks]
y_coordinates = [landmark.y for landmark in hand_landmarks]
text_x = int(min(x_coordinates) * width)
text_y = int(min(y_coordinates) * height) - MARGIN
# Draw handedness (left or right hand) on the image.
cv2.putText(annotated_image, f"{handedness[0].category_name}", (text_x, text_y), cv2.FONT_HERSHEY_DUPLEX,
FONT_SIZE, HANDEDNESS_TEXT_COLOR, FONT_THICKNESS, cv2.LINE_AA)
return annotated_image
# Create an HandLandmarker object.
base_options = python.BaseOptions(model_asset_path='hand_landmarker.task')
# https://ai.google.dev/edge/mediapipe/solutions/vision/hand_landmarker
options = vision.HandLandmarkerOptions(base_options=base_options, num_hands=2)
detector = vision.HandLandmarker.create_from_options(options)
# Load the input image.
image = mp.Image.create_from_file("hand.jpg")
#cv_image = cv2.imread('hand.jpg')
#image = mp.Image(image_format = mp.ImageFormat.SRGB,
# data = cv2.cvtColor(cv_image, cv2.COLOR_BGR2RGB))
# https://ai.google.dev/edge/api/mediapipe/python/mp/Image
# Detect hand landmarks from the input image.
detection_result = detector.detect(image)
# Process the classification result. In this case, visualize it.
annotated_image = draw_landmarks_on_image(image.numpy_view(), detection_result)
cv2.imshow('sean', cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR))
cv2.waitKey(0)
|
소스를 입력하고 실행한다.

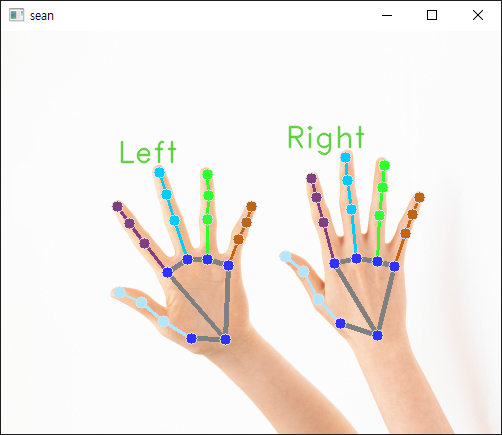
반응형