
[Python] JSON 분석, 추출, 변환
AI, ML, DL 2019. 1. 18. 20:14 |반응형
Python 기본 라이브러리 json을 이용해 JSON (JavaScript Object Notation) 형식을 분석할 수 있다.
import urllib.request as req
import os.path
import json
url = "https://api.github.com/repositories"
filename = "repositories.json"
if not os.path.exists(filename):
#req.urlretrieve(url, filename)
# Legacy interface. It might become deprecated at some point in the future.
with req.urlopen(url) as contents:
jsn = contents.read().decode("utf-8") # .decode("utf-8")이 없으면 jsn에는 str이 아닌 bytes가 저장 된다.
# If the end of the file has been reached, read() will return an empty string ('').
print(jsn)
# print(json.dumps(jsn, indent="\t")) 는 indent가 적용되어 출력되어야 하지만 원본이 indent가 적용되어 있지
# 않아 indent 없이 출력 된다.
with open(filename, mode="wt", encoding="utf-8") as f:
f.write(jsn)
with open(filename, mode="rt", encoding="utf-8") as f:
items = json.load(f) # JSON 문서를 갖고 있는 파일 포인터 전달. loads()는 JSON 형식의 문자열 전달
for item in items:
print("Name:", item["name"], "Login:", item["owner"]["login"])
test = {
"Date" : "2019-01-17",
"Time" : "21:30:24",
"Location" : {
"Town" : "Franklin",
"City" : "Newyork",
"Country" : "USA"
}
}
s = json.dumps(test, indent="\t")
# Serialize obj to a JSON formatted str
# If indent is a non-negative integer or string, then JSON array elements and object members will be pretty-printed
# with that indent level. An indent level of 0, negative, or "" will only insert newlines. None (the default) selects
# the most compact representation. Using a positive integer indent indents that many spaces per level. If indent is a
# string (such as "\t"), that string is used to indent each level.
print(s)
with open("dump.json", mode="wt") as f:
json.dump(test, f, indent="\t")
# Serialize obj as a JSON formatted stream to fp (a .write()-supporting file-like object)
출력 결과 처음 부분.

출력 결과 마지막 부분.

write()으로 만든 repositories.json과 dump()으로 만든 dump.json 파일.

json파일에서 필요한 부분을 추출하고 다른 파일로 변환해 보자.
20210817_RGB_N_011_45_01.json
0.02MB
위 파일은 AI 농작물 관련 잡초 레이블 파일이다. YOLO에서 훈련하기 위해서는 객체 클래스와 바운딩 박스의 정보만 필요한데, 불필요한 정보가 섞여 있다. 필요한 정보만 추출해 txt 파일로 저장해 보자.

import json
filename = '20210817_RGB_N_011_45_01.json'
with open(filename, 'r', encoding='UTF-8') as f:
data = json.load(f)
#print(data)
#print(json.dumps(data, ensure_ascii=False, indent='\t'))
#ensure_ascii=False : 한글 문자를 아스키 형태의 문자열로 변경 금지
#indent='\t' : 들여쓰기, '\t' 외 숫자를 넣어도 된다
print("weeds_kind: " + data["annotations"]["weeds_kind"])
print("bbox: " + str(data["annotations"]["bbox"]))
#print(data["annotations"]["bbox"][0])
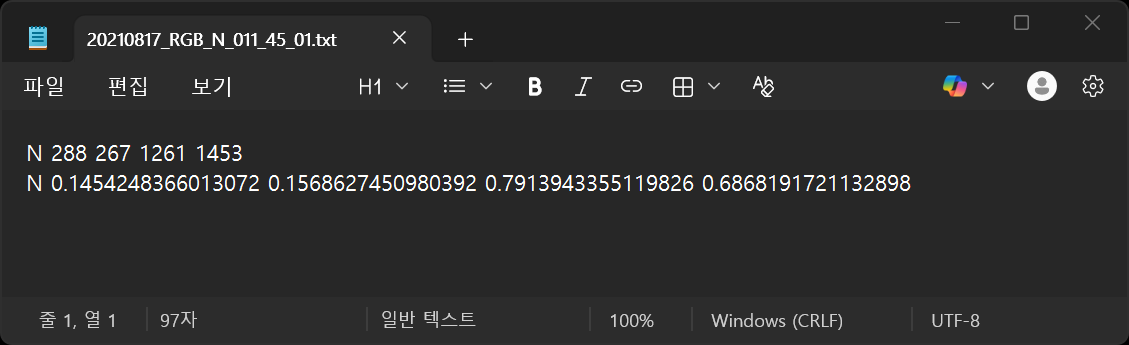
simple = str(data["annotations"]["weeds_kind"] + ' ' + ' '.join(str(int(s)) for s in data["annotations"]["bbox"]))
# - join()
# 리스트의 모든 요소를 합쳐 작은 따옴표('')사이의 문자로 구분된 하나의 문자열을 반환한다.
# 리스트의 요소는 string이어야 한다.
# data["annotations"]["bbox"]의 요소는 float이다. int로 변환하고 다시 문자열로 변환한다.
print("simple string: " + simple)
# 좌표값을 비율로 나타내기
width = data["images"]["img_width"]
height = data["images"]["img_height"]
top = data["annotations"]["bbox"][1]
left = data["annotations"]["bbox"][0]
bottom = data["annotations"]["bbox"][3]
right = data["annotations"]["bbox"][2]
rtop = top / height
rleft = left / width
rbottom = bottom / height
rright = right / width
rsimple = ' '.join([data["annotations"]["weeds_kind"], str(rtop), str(rleft), str(rbottom), str(rright)])
print("rsimple: " + rsimple)
# 파일 출력
filename = filename.replace('.json', '.txt')
#filename = filename[0:-4].__add__('txt') # filename[0:-4] + '.txt'
#filename = filename.removesuffix('.json')
#filename = filename.__add__('.txt') # filename + '.txt'
with open(filename, 'w', encoding='UTF-8') as f:
f.write(simple + '\n')
f.write(rsimple)

반응형
'AI, ML, DL' 카테고리의 다른 글
| OCR with Tesseract on Windows - Windows에서 테서랙트 사용하기 (0) | 2020.10.07 |
|---|---|
| [Python] CSV 분석 (0) | 2019.01.20 |
| Beautifulsoup XML 분석 (0) | 2019.01.15 |
| [Scraping] Selenium으로 로그인이 필요한 사이트(Yes24) 정보 가져오기 (0) | 2019.01.01 |
| [Scraping] Naver '이 시각 주요 뉴스' 목록 가져 오기 (0) | 2018.12.30 |