from selenium import webdriver
from selenium.webdriver.common.by import By
url = "https://www.knou.ac.kr/knou/561/subview.do"
# 드라이버 옵션 설정
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(options=options)
# 웹페이지 열기
driver.get(url)
#driver.implicitly_wait(10)
#contents = driver.page_source
# 제목 추출
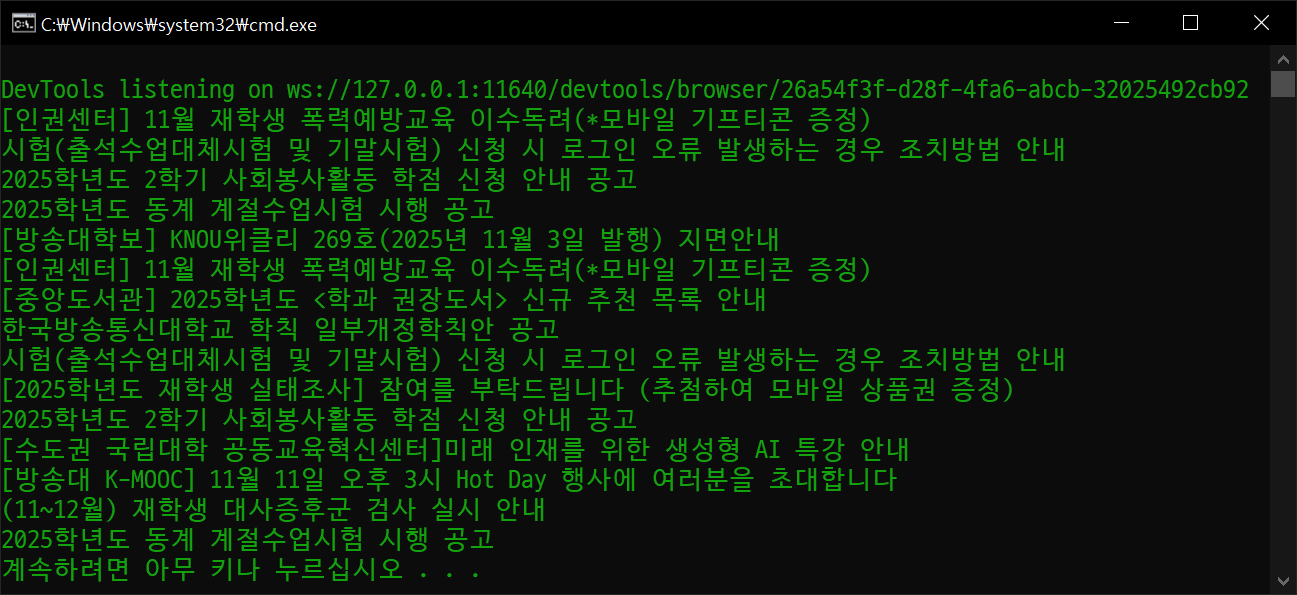
titles = driver.find_elements(By.XPATH, '//td[@class="td-subject"]/a/strong')
#title = driver.find_element(By.XPATH, '//td[@class="td-subject"]/a/strong')
#print(title.text)
# 모든 제목 출력
# for title in titles:
# print(title.text)
# find_elements로 찾은 리스트를 그대로 출력하면 WebElement 객체들이 출력됨.
# 따라서 각 객체의 text 속성을 출력해야 실제 텍스트가 출력됨.
for title in titles:
print(title)
driver.quit()
다음 페이지 제목 리스트까지 가져와 보자.
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
url = "https://www.knou.ac.kr/knou/561/subview.do"
# 드라이버 옵션 설정
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(options=options)
# 웹페이지 열기
driver.get(url)
#driver.implicitly_wait(10)
#contents = driver.page_source
# 제목 추출
temp = driver.find_elements(By.XPATH, '//td[@class="td-subject"]/a/strong')
result = [title.text for title in temp]
# 다음 페이지로 이동해서 제목 추출
next_button = driver.find_element(By.CLASS_NAME, '_listNext')
if next_button and next_button.is_enabled():
next_button.click()
# 페이지 로딩 대기(안해도 되는 경우도 있음)
WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'board-table')))
#WebDriverWait(driver, 10).until(lambda d: d.find_element(By.XPATH, '//td[@class="td-subject"]/a/strong'))
temp = driver.find_elements(By.XPATH, '//td[@class="td-subject"]/a/strong')
titles = [title.text for title in temp]
result.extend(titles)
# 모든 제목 출력
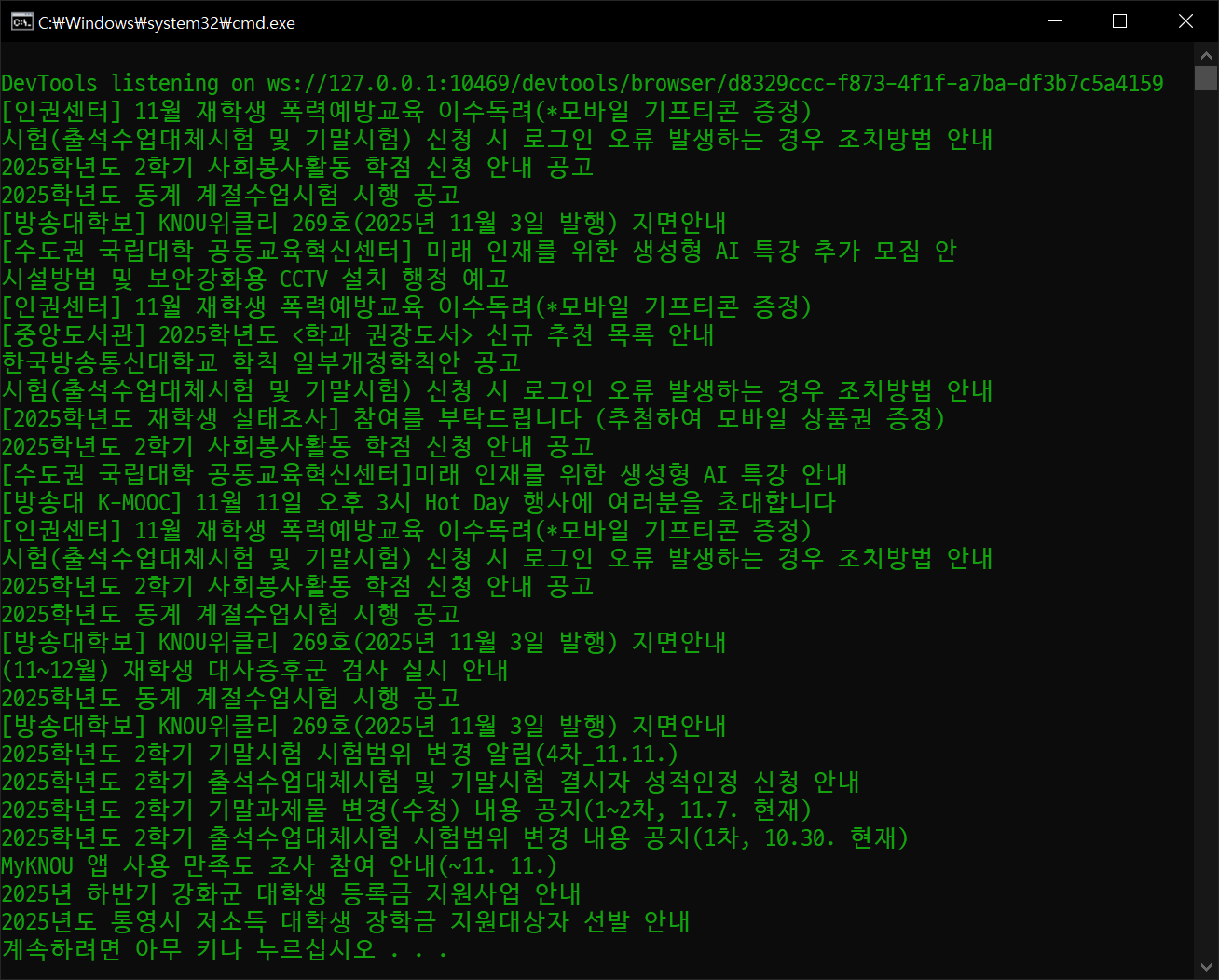
for title in result:
print(title)
driver.close()
게시판 두 번째 페이지까지 제목 리스트
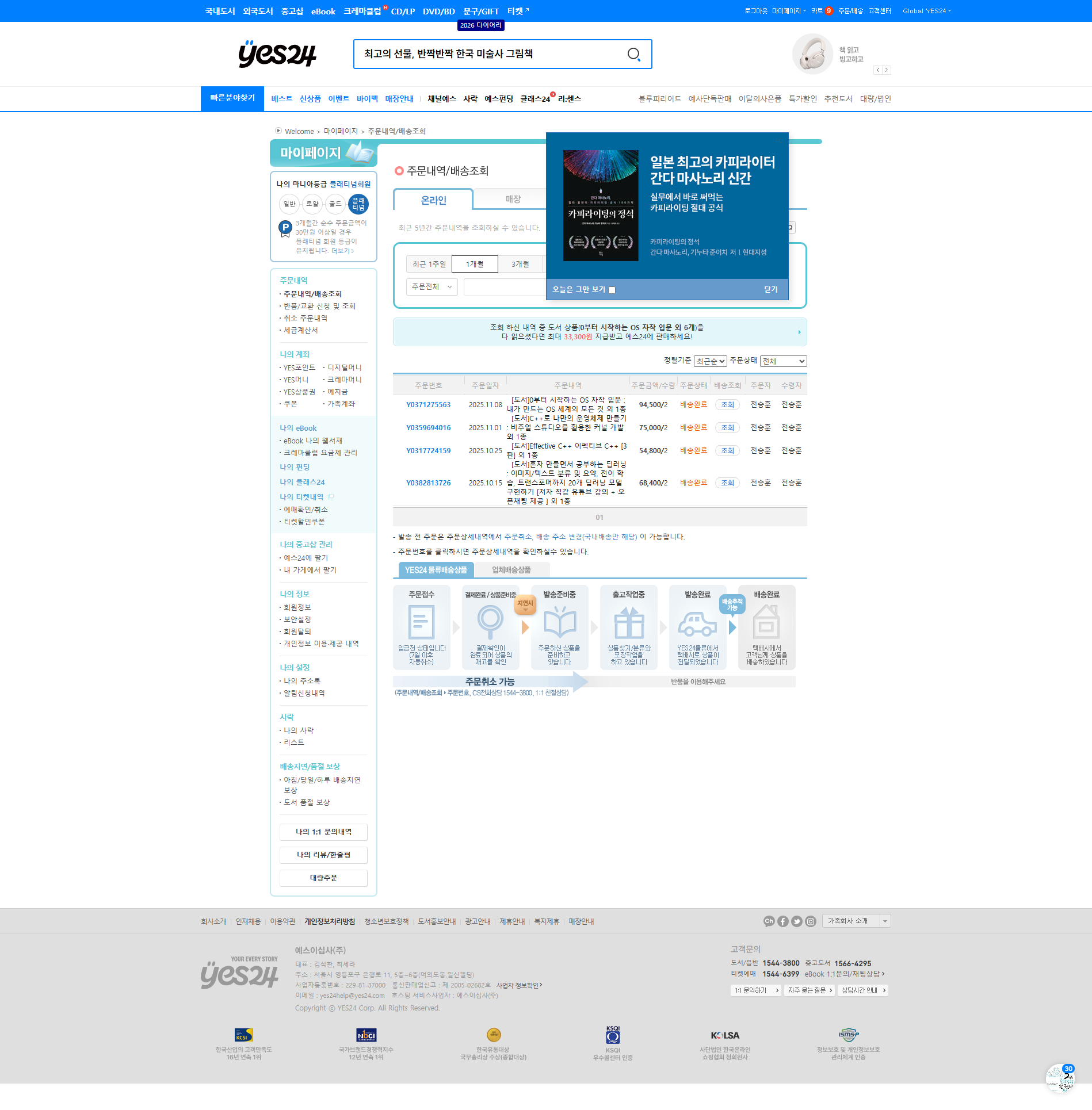
이번엔 인터넷 서점(Yes24)에 접속해서 로그인 하고 주문 내역을 가져 온다.
Chrome이 동작하는걸 보고 싶다면 options - headless 부분만 삭제하면 된다.
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "https://www.yes24.com/Templates/FTLogin.aspx"
id = "Your_ID"
password = "Your_Password"
# Selenium WebDriver 설정
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--window-size=1920,2080")
driver = webdriver.Chrome(options=options)
# 로그인 페이지로 이동
driver.get(url)
#driver.implicitly_wait(10)
#contents = driver.page_source
#print(contents)
# 로그인
id_elmt = driver.find_element(By.ID, 'SMemberID')
id_elmt.send_keys(id)
pass_elmt = driver.find_element(By.ID, 'SMemberPassword')
pass_elmt.send_keys(password)
login_elmt = driver.find_element(By.ID, 'btnLogin')
login_elmt.click()
#driver.implicitly_wait(10)
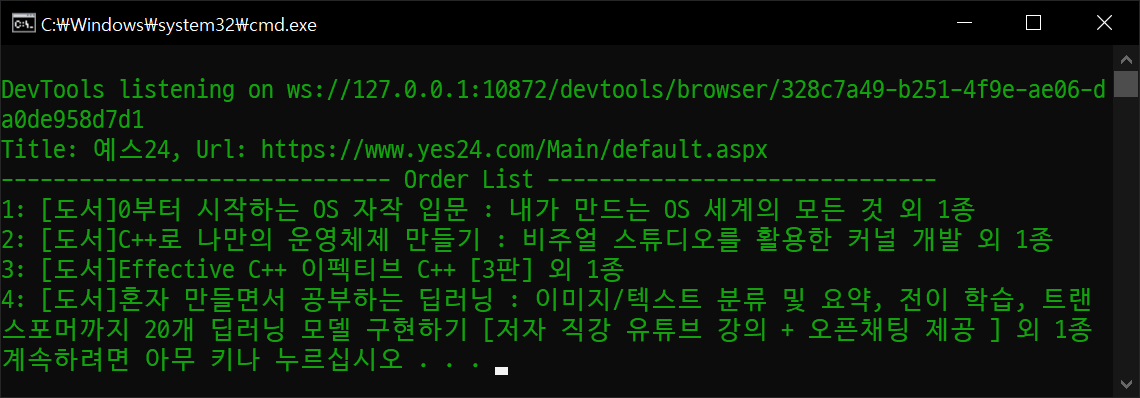
print(f"Title: {driver.title}, Url: {driver.current_url}")
# 주문/배송 페이지로 이동
order_list_page_elmt = driver.find_element(By.LINK_TEXT, '주문/배송')
order_list_page_elmt.click()
#list_url = "https://ssl.yes24.com/dMyPage/MyPageOrderList"
#driver.get(list_url)
# 주문 내역 추출
print("-"*30 + " Order List " + "-"*30)
#order_titles = driver.find_elements(By.XPATH, '//table[@id="MyOrderListTbl"]')
#order_titles = driver.find_elements(By.XPATH, '//span[@class="txt120"]')
order_titles = driver.find_elements(By.CLASS_NAME, 'txt120')
for idx, order_title in enumerate(order_titles):
print(f"{idx+1}: {order_title.text}")
# 스크린샷 저장
driver.save_screenshot("yes24_order_list.png")
driver.quit()