
[Ollama] Ollama with Python 1
AI, ML, DL 2026. 6. 13. 22:33 |반응형
파이썬에서 Ollama를 사용해 보자.
2026.06.13 - [AI, ML, DL] - [Ollama] Ollama 설치 및 간단한 실행
2026.06.14 - [AI, ML, DL] - [Ollama] Ollama with Python 2
import requests
import json
url = "http://localhost:11434/api/generate" # 엔드포인트 URL
# generate는 모델이 텍스트를 생성하는 것을 의미한다.
# 이 엔드포인트는 모델에게 텍스트 생성을 요청하는 역할을 한다.
# 예를 들어, 사용자가 "What is the capital of France?"라는 질문을 보내면, 모델은 이에 대한 답변을 생성하여 반환하게 된다.
payload = {
"model": "llava",
"prompt": "What is the capital of France?",
"stream": False # 스트리밍 여부를 설정하는 옵션으로, False로 설정하면 모델이 생성한 텍스트를 한 번에 반환한다.
# True로 설정하면 모델이 텍스트를 생성하는 동안 실시간으로 결과를 스트리밍 방식으로 받을 수 있다.
}
headers = { "Content-Type": "application/json" }
response = requests.post(url, data=json.dumps(payload), headers=headers)
if response.status_code == 200:
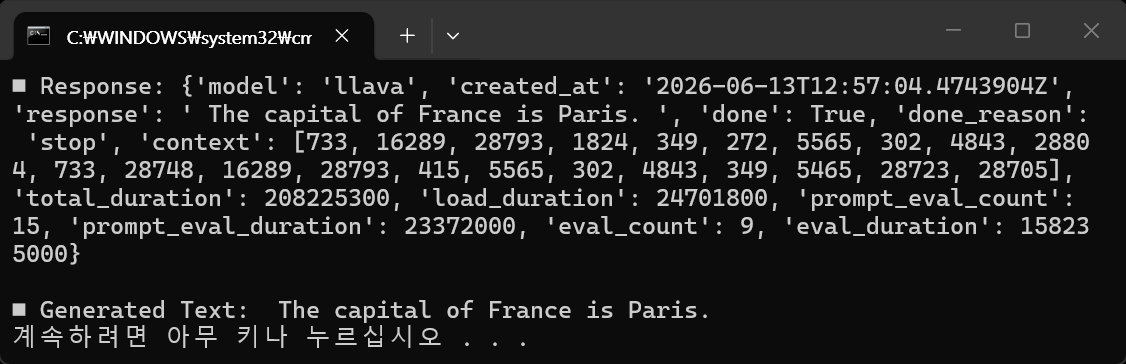
print("■ Response:", response.json())
print()
print("■ Generated Text:", response.json().get("response", "No generated text found"))
# response.json().get("response", "No generated text found")는 JSON 응답에서 "response" 키에 해당하는 값을 가져오며,
# 만약 해당 키가 존재하지 않을 경우 "No generated text found"라는 기본값을 반환한다.
else:
print("Error:", response.status_code, response.text)
import requests
import json
url = "http://localhost:11434/api/generate"
payload = {
"model": "llava",
"prompt": "What is the capital of France?",
"stream": True # 스트리밍 여부를 설정하는 옵션으로, False로 설정하면 모델이 생성한 텍스트를 한 번에 반환한다.
# True로 설정하면 모델이 텍스트를 생성하는 동안 실시간으로 결과를 스트리밍 방식으로 받을 수 있다.
}
headers = { "Content-Type": "application/json" }
response = requests.post(url, data=json.dumps(payload), headers=headers, stream=True)
if response.status_code == 200:
print("Response:", end=" ")
# 줄 단위로 데이터를 읽어옴
for line in response.iter_lines():
if line:
# 바이트 데이터를 문자열로 디코딩
text = line.decode('utf-8')
result = json.loads(text)
# 모델이 생성한 텍스트를 출력
print(result.get("response", ""), end=" ", flush=True)
else:
print("Error:", response.status_code, response.text)

인공지능과 연속적인 대화를 나눠 보자.
import requests
import json
url = "http://localhost:11434/api/chat" # chat은 챗봇과의 대화를 의미하는 것으로, 이 API 엔드포인트는 챗봇과의
# 상호작용을 처리하는 역할을 한다. 클라이언트가 이 URL로 POST 요청을 보내면, 서버는 챗봇 모델을 사용하여 질문에
# 대한 답변을 생성하고 이를 응답으로 반환한다.
payload = {
"model": "llava",
"messages": [
{
"role": "system",
"content": "너는 친절한 조수야. 네 이름이 뭐야?"
},
{
"role": "user",
"content": "한국의 수도는 어디야?"
}
],
"stream": False
}
headers = { "Content-Type": "application/json" }
response = requests.post(url, data=json.dumps(payload), headers=headers)
if response.status_code == 200:
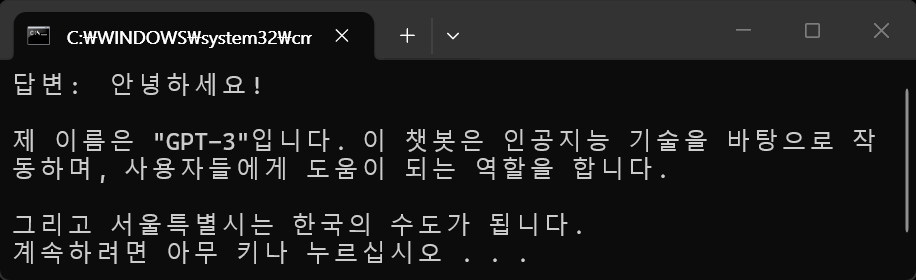
result = response.json()
print("답변:", result.get("message", {}).get("content", ""))
# 챗봇이 생성한 답변은 JSON 응답의 "message" 필드 내의 "content" 필드에 포함되어 있다. 따라서, result.get("message", {}).get("content", "") 코드를 사용하여 답변을 추출하고 출력한다.
# {}는 get 메서드에서 기본값으로 빈 딕셔너리를 제공하여, "message" 키가 존재하지 않을 경우에도 오류 없이 빈 딕셔너리를 반환하도록 한다. 그리고 다시 get("content", "")를 사용하여 "content" 키가 존재하지 않을 경우 빈 문자열을 반환하도록 한다.
else:
print("Error:", response.status_code, response.text)

이미지를 분석해 보자.
import requests
import json
import base64
# Ollama의 llava와 같은 멀티모달(시각-언어) 모델에 이미지를 전달하려면, 이미지 파일의 경로를 프롬프트에 텍스트로 적는 것이
# 아니라 이미지 파일을 읽어서 Base64 방식으로 인코딩한 뒤, 페이로드의 images 배열 매개변수로 전달해야 한다.
# 로컬 이미지 파일을 읽어 Base64로 인코딩
image_path = r"D:\D\My project\C\bus.jpg"
with open(image_path, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
url = "http://localhost:11434/api/generate" # 엔드포인트 URL
# generate는 모델이 텍스트를 생성하는 것을 의미한다.
# 이 엔드포인트는 모델에게 텍스트 생성을 요청하는 역할을 한다.
# 예를 들어, 사용자가 "What is the capital of France?"라는 질문을 보내면, 모델은 이에 대한 답변을 생성하여 반환하게 된다.
payload = {
"model": "llava",
"prompt": "이 사진은 어디서 찍었을까? 한글로 대답해줘.",
"stream": False, # 스트리밍 여부를 설정하는 옵션으로, False로 설정하면 모델이 생성한 텍스트를 한 번에 반환한다.
"images": [base64_image] # Base64 문자열로 인코딩된 이미지를 리스트 형태로 전달
}
headers = { "Content-Type": "application/json" }
response = requests.post(url, data=json.dumps(payload), headers=headers)
if response.status_code == 200:
print("Response:", response.json().get("response", "No generated text found"))
# response.json().get("response", "No generated text found")는 JSON 응답에서 "response" 키에 해당하는 값을 가져오며,
# 만약 해당 키가 존재하지 않을 경우 "No generated text found"라는 기본값을 반환한다.
else:
print("Error:", response.status_code, response.text)


반응형
'AI, ML, DL' 카테고리의 다른 글
| [Ollama] Hugging Face 모델 설치 (Bllossom) (0) | 2026.06.14 |
|---|---|
| [Ollama] Ollama with Python 2 (0) | 2026.06.14 |
| [Ollama] Ollama 설치 및 간단한 실행 (0) | 2026.06.13 |
| [Tensorflow] Keras mnist dataset with OpenCV 케라스 데이터세트 (feat. LeNet-5) (0) | 2026.03.02 |
| [Tensorflow] Kernel build 커널 빌드 및 확인 (0) | 2026.03.01 |