[MediaPipe] Async Pose Landmark Detection 비동기 자세 특징 감지
AI, ML, DL 2025. 2. 12. 09:49 |반응형
동기 함수인 detect()를 사용해 카메라 영상 내 사람의 자세를 감지해 보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
import numpy as np
import cv2
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
def draw_landmarks_on_image(rgb_image, detection_result, bg_black):
pose_landmarks_list = detection_result.pose_landmarks
# Black Background
if bg_black:
annotated_image = np.zeros_like(rgb_image)
else:
annotated_image = np.copy(rgb_image)
# Loop through the detected poses to visualize.
for idx in range(len(pose_landmarks_list)):
pose_landmarks = pose_landmarks_list[idx]
# Draw the pose landmarks.
pose_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
pose_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in pose_landmarks
])
solutions.drawing_utils.draw_landmarks(
annotated_image,
pose_landmarks_proto,
solutions.pose.POSE_CONNECTIONS,
solutions.drawing_styles.get_default_pose_landmarks_style())
return annotated_image
# Create an PoseLandmarker object.
base_options = python.BaseOptions(model_asset_path='pose_landmarker_full.task')
options = vision.PoseLandmarkerOptions(base_options=base_options, output_segmentation_masks=True)
detector = vision.PoseLandmarker.create_from_options(options)
cap = cv2.VideoCapture(0)
while True:
# Load the input frame.
ret, cv_frame = cap.read()
if not ret:
break
frame = mp.Image(image_format = mp.ImageFormat.SRGB, data = cv2.cvtColor(cv_frame, cv2.COLOR_BGR2RGB))
# Detect pose landmarks from the input image.
detection_result = detector.detect(frame)
# Process the detection result. In this case, visualize it.
annotated_frame = draw_landmarks_on_image(frame.numpy_view(), detection_result, True)
cv2.imshow('sean', cv2.cvtColor(annotated_frame, cv2.COLOR_RGB2BGR))
key = cv2.waitKey(25)
if key == 27: # ESC
break
if cap.isOpened():
cap.release()
cv2.destroyAllWindows()
|
이번엔 비동기 detect_async()를 사용해 자세를 감지해 보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
import time
import numpy as np
import cv2
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
landmark_result = None
# The user-defined result callback for processing live stream data.
# The result callback should only be specified when the running mode is set to the live stream mode.
# The result_callback provides:
# The pose landmarker detection results.
# The input image that the pose landmarker runs on.
# The input timestamp in milliseconds.
def print_result(result: vision.PoseLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
global landmark_result
landmark_result = result
#print(output_image.numpy_view())
# output_image에 접근은 가능하지만 이 콜백 함수에서 cv2.imshow()를 이용한 이미지 출력은 안되는거 같다.
# 여러가지 방법으로 해 봤지만 정상적인 작동은 되지 않는다.
# Structure of PoseLandmakerResult
# mp.tasks.vision.PoseLandmarkerResult(
# pose_landmarks: List[List[landmark_module.NormalizedLandmark]],
# pose_world_landmarks: List[List[landmark_module.Landmark]],
# segmentation_masks: Optional[List[image_module.Image]] = None
# )
#print('pose landmarker result: {}'.format(result))
#print("pose landmark: ", result.pose_landmarks[0][0].visibility)
#print("pose world landmark: ", result.pose_world_landmarks[0][0].visibility)
# pose_landmarks_list = result.pose_landmarks
# for idx in range(len(pose_landmarks_list)):
# pose_landmarks = pose_landmarks_list[idx]
# for landmark in pose_landmarks:
# print("x: %.2f, y: %.2f, z: %.2f visibility: %.2f, presence: %.2f" %(landmark.x, landmark.y,
# landmark.z, landmark.visibility, landmark.presence))
def draw_landmarks_on_image(rgb_image, detection_result, bg_black):
# Black Background
if bg_black:
annotated_image = np.zeros_like(rgb_image)
else:
annotated_image = np.copy(rgb_image)
# 비동기 detect_async()가 사용 되었기 때문에 처음 몇 프레임은 detection_result가 None일 수 있다.
# 또, 이미지(프레임)에 사람이 없을땐 detection_result.pose_landmarks 리스트가 비어있게 된다.
# 그에 대한 처리를 하지 않으면 에러가 발생한다.
if detection_result is None or detection_result.pose_landmarks == []:
return annotated_image
pose_landmarks_list = detection_result.pose_landmarks
# Loop through the detected poses to visualize.
for idx in range(len(pose_landmarks_list)):
pose_landmarks = pose_landmarks_list[idx]
# Draw the pose landmarks.
pose_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
pose_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in pose_landmarks
])
solutions.drawing_utils.draw_landmarks(
annotated_image,
pose_landmarks_proto,
solutions.pose.POSE_CONNECTIONS,
solutions.drawing_styles.get_default_pose_landmarks_style())
return annotated_image
base_options = python.BaseOptions(model_asset_path='pose_landmarker_full.task')
options = vision.PoseLandmarkerOptions(base_options=base_options,running_mode=mp.tasks.vision.RunningMode.LIVE_STREAM,
result_callback=print_result, output_segmentation_masks=False)
# The running mode of the task. Default to the image mode. PoseLandmarker has three running modes:
# 1) The image mode for detecting pose landmarks on single image inputs.
# 2) The video mode for detecting pose landmarks on the decoded frames of a video.
# 3) The live stream mode for detecting pose landmarks on the live stream of input data, such as from camera.
# In this mode, the "result_callback" below must be specified to receive the detection results asynchronously.
detector = vision.PoseLandmarker.create_from_options(options)
cap = cv2.VideoCapture(0)
while True:
ret, cv_image = cap.read()
if not ret:
break
frame = mp.Image(image_format = mp.ImageFormat.SRGB, data = cv2.cvtColor(cv_image, cv2.COLOR_BGR2RGB))
# Sends live image data to perform pose landmarks detection.
# The results will be available via the "result_callback" provided in the PoseLandmarkerOptions.
# Only use this method when the PoseLandmarker is created with the live stream running mode.
# Only use this method when the PoseLandmarker is created with the live stream running mode.
# The input timestamps should be monotonically increasing for adjacent calls of this method.
# This method will return immediately after the input image is accepted. The results will be available via
# the result_callback provided in the PoseLandmarkerOptions. The detect_async method is designed to process
# live stream data such as camera input. To lower the overall latency, pose landmarker may drop the input
# images if needed. In other words, it's not guaranteed to have output per input image.
detector.detect_async(frame, int(time.time()*1000))
annotated_image = draw_landmarks_on_image(frame.numpy_view(), landmark_result, True)
cv2.imshow('sean', cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR))
key = cv2.waitKey(25)
if key == 27: # ESC
break
if cap.isOpened():
cap.release()
cv2.destroyAllWindows()
detector.close()
|
이번엔 감지한 자세를 부위별로 나눠 위치 정보를 표시해 보자.
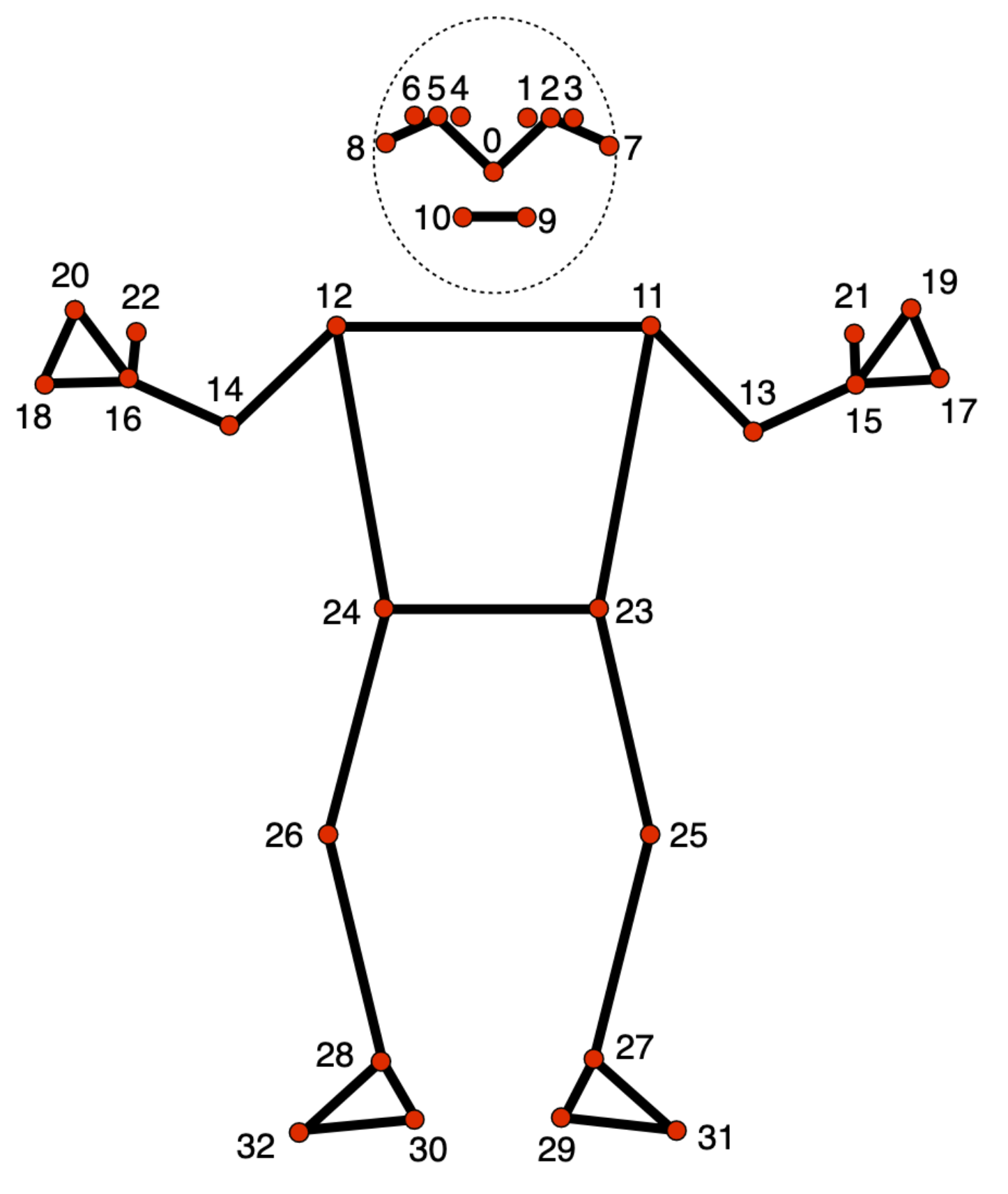
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
import time
import numpy as np
import cv2
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
landmark_result = None
def print_result(result: vision.PoseLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
global landmark_result
landmark_result = result
if result is None or result.pose_landmarks == []:
return
print(" Nose(0): (x: %.2f, y: %.2f, z: %5.2f, presense: %.2f, visibility: %.2f)"
%(result.pose_landmarks[0][0].x, result.pose_landmarks[0][0].y, result.pose_landmarks[0][0].z,
result.pose_landmarks[0][0].presence, result.pose_landmarks[0][0].visibility))
print("Right Knee(26): (x: %.2f, y: %.2f, z: %5.2f, presense: %.2f, visibility: %.2f)"
%(result.pose_landmarks[0][26].x, result.pose_landmarks[0][26].y, result.pose_landmarks[0][26].z,
result.pose_landmarks[0][26].presence, result.pose_landmarks[0][26].visibility))
def draw_landmarks_on_image(rgb_image, detection_result, bg_black):
if bg_black:
annotated_image = np.zeros_like(rgb_image)
else:
annotated_image = np.copy(rgb_image)
if detection_result is None or detection_result.pose_landmarks == []:
return annotated_image
pose_landmarks_list = detection_result.pose_landmarks
for idx in range(len(pose_landmarks_list)):
pose_landmarks = pose_landmarks_list[idx]
pose_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
pose_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in pose_landmarks
])
solutions.drawing_utils.draw_landmarks(
annotated_image,
pose_landmarks_proto,
solutions.pose.POSE_CONNECTIONS,
solutions.drawing_styles.get_default_pose_landmarks_style())
return annotated_image
base_options = python.BaseOptions(model_asset_path='pose_landmarker_full.task')
options = vision.PoseLandmarkerOptions(base_options=base_options,running_mode=mp.tasks.vision.RunningMode.LIVE_STREAM,
result_callback=print_result, output_segmentation_masks=False)
detector = vision.PoseLandmarker.create_from_options(options)
cap = cv2.VideoCapture(0)
while True:
ret, cv_image = cap.read()
if not ret:
break
frame = mp.Image(image_format = mp.ImageFormat.SRGB, data = cv2.cvtColor(cv_image, cv2.COLOR_BGR2RGB))
detector.detect_async(frame, int(time.time()*1000))
annotated_image = draw_landmarks_on_image(frame.numpy_view(), landmark_result, True)
cv2.imshow('sean', cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR))
key = cv2.waitKey(25)
if key == 27: # ESC
break
if cap.isOpened():
cap.release()
cv2.destroyAllWindows()
detector.close()
|
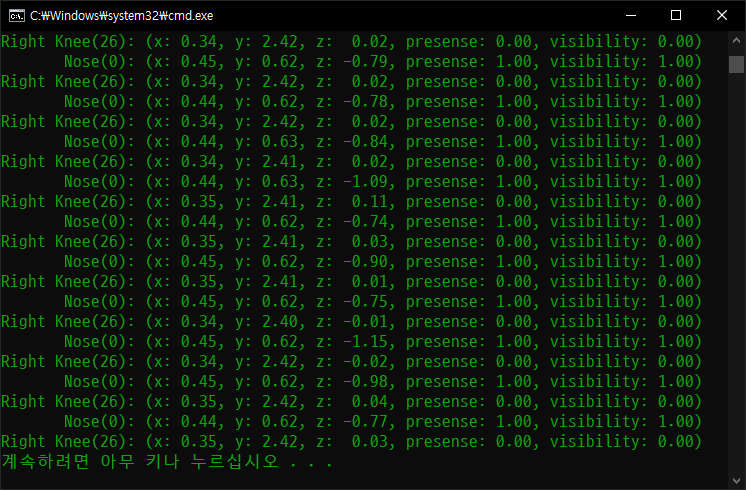
- The output contains the following normalized coordinates (Landmarks):
- x and y: Landmark coordinates normalized between 0.0 and 1.0 by the image width (x) and height (y).
- z: The landmark depth, with the depth at the midpoint of the hips as the origin. The smaller the value, the closer the landmark is to the camera. The magnitude of z uses roughly the same scale as x.
- visibility: The likelihood of the landmark being visible within the image.
※ 참고
A Tutorial on Finger Counting in Real-Time Video in Python with OpenCV and MediaPipe
반응형
'AI, ML, DL' 카테고리의 다른 글
| [MediaPipe] Face Landmark Detection 얼굴 특징 감지 (1) | 2025.02.11 |
|---|---|
| [MediaPipe] Pose Landmark Detection 자세 특징 감지 (0) | 2025.02.11 |
| [MediaPipe] Face Detection 얼굴 감지 (0) | 2025.02.11 |
| [MediaPipe] Hand Landmark Detection 손 특징 감지 (0) | 2025.02.11 |
| [MediaPipe] Object Detection 객체 감지 (1) | 2025.02.11 |