
[Ollama] llava 동영상 분석
AI, ML, DL 2026. 6. 14. 15:23 |파이썬 Ollama 라이브러리를 이용해 llava로 동영상을 분석해 보자.
LLaVA 모델은 기본적으로 이미지 인식(Vision) 모델이기 때문에, MP4 비디오 파일 자체를 한 번에 입력받아 분석할 수는 없다. 대신 OpenCV 같은 라이브러리를 사용하여 비디오에서 특정 프레임(이미지)을 추출한 뒤, 해당 이미지를 LLaVA 모델에 전달하여 상황을 분석하는 방식을 사용해야 한다.
import cv2
import ollama
def analyze_video_frame(video_path, frame_number=0):
# 비디오에서 특정 프레임을 추출하여 LLaVA 모델로 분석합니다.
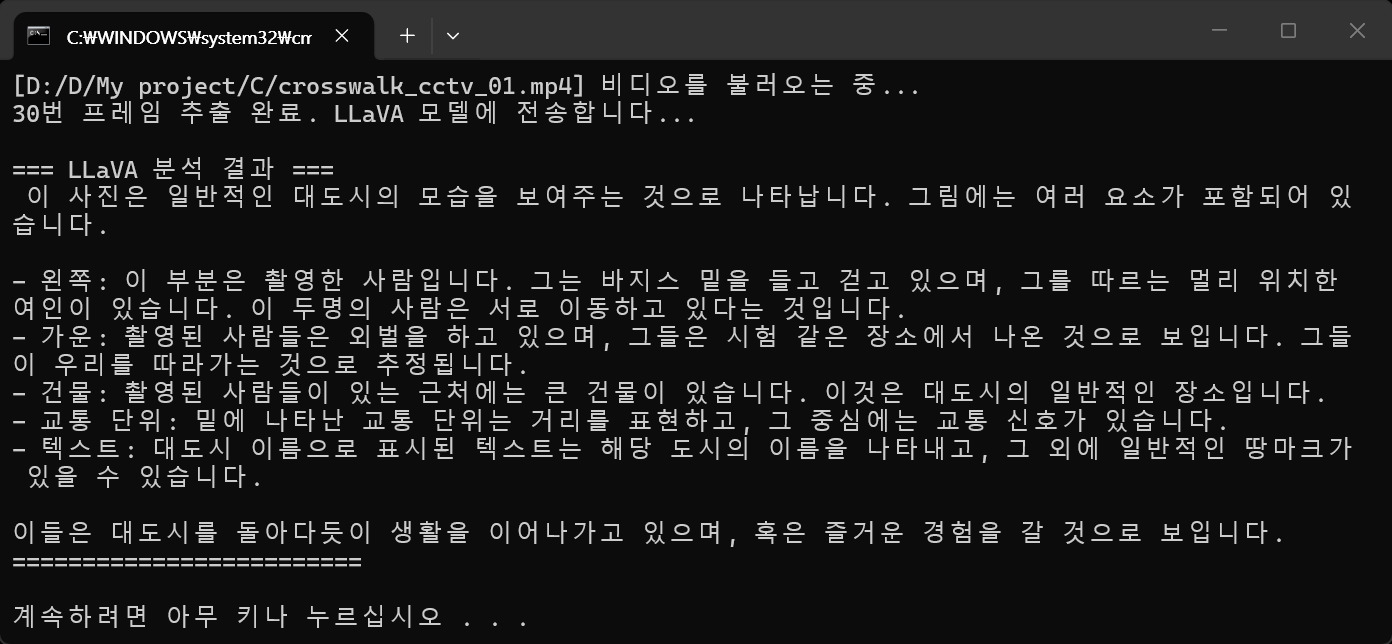
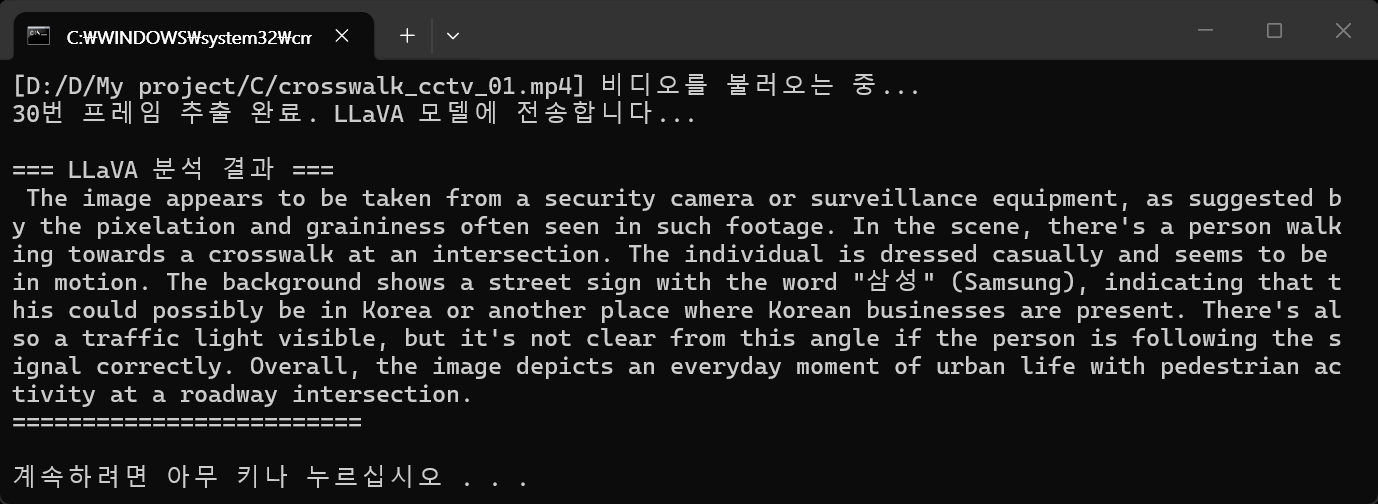
print(f"[{video_path}] 비디오를 불러오는 중...")
# 비디오 파일 열기
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print("오류: 비디오 파일을 열 수 없습니다. 경로를 확인해주세요.")
return
# 원하는 프레임 위치로 이동하여 읽기
cap.set(cv2.CAP_PROP_POS_FRAMES, frame_number)
ret, frame = cap.read()
cap.release()
if not ret:
print(f"오류: {frame_number}번 프레임을 읽을 수 없습니다.")
return
print(f"{frame_number}번 프레임 추출 완료. LLaVA 모델에 전송합니다...")
# OpenCV 이미지(NumPy 배열)를 JPEG 바이트 데이터로 인코딩
# Ollama API는 바이트 형태의 이미지 데이터를 직접 받을 수 있다.
success, buffer = cv2.imencode('.jpg', frame)
# 물리적인 이미지 파일을 생성하지 않는다.
if not success:
print("오류: 프레임 인코딩에 실패했습니다.")
return
frame_bytes = buffer.tobytes()
# Ollama LLaVA 모델에 프롬프트와 이미지 전달
#prompt_text = "이 이미지에서 어떤 상황이 벌어지고 있는지 한국어로 자세히 설명해줘."
prompt_text = "이 이미지에서 어떤 상황이 벌어지고 있는지 자세히 설명해줘."
try:
response = ollama.chat(
model='llava',
messages=[
{
'role': 'user',
'content': prompt_text,
'images': [frame_bytes]
}
]
)
# 결과 출력
print("\n=== LLaVA 분석 결과 ===")
print(response['message']['content'])
print("========================\n")
except Exception as e:
print(f"Ollama 실행 중 오류 발생: {e}")
if __name__ == "__main__":
video_file = "D:/D/My project/C/crosswalk_cctv_01.mp4" # 분석할 비디오 파일 경로
target_frame = 30 # 분석하고 싶은 프레임 번호 (예: 1초가 30FPS라면 1초 시점)
analyze_video_frame(video_file, target_frame)
하나의 동영상에서 일정한 시간 간격으로 프레임을 추출해 전체적인 흐름을 분석해 보자.
import cv2
import ollama
def analyze_video_flow(video_path, interval_sec=5):
# 비디오에서 일정 시간(초) 간격으로 프레임을 추출해 전체 흐름을 LLaVA 모델로 분석한다.
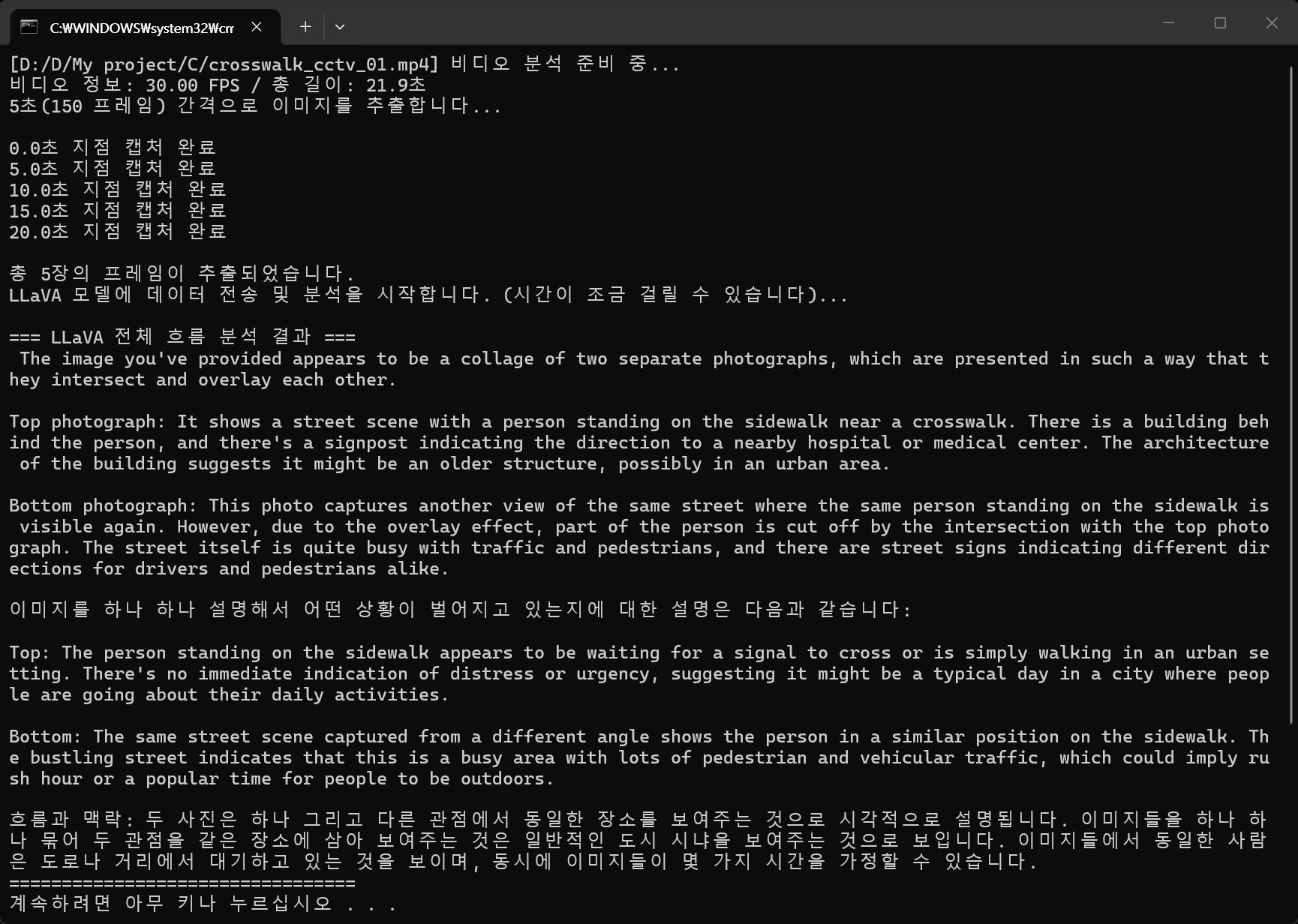
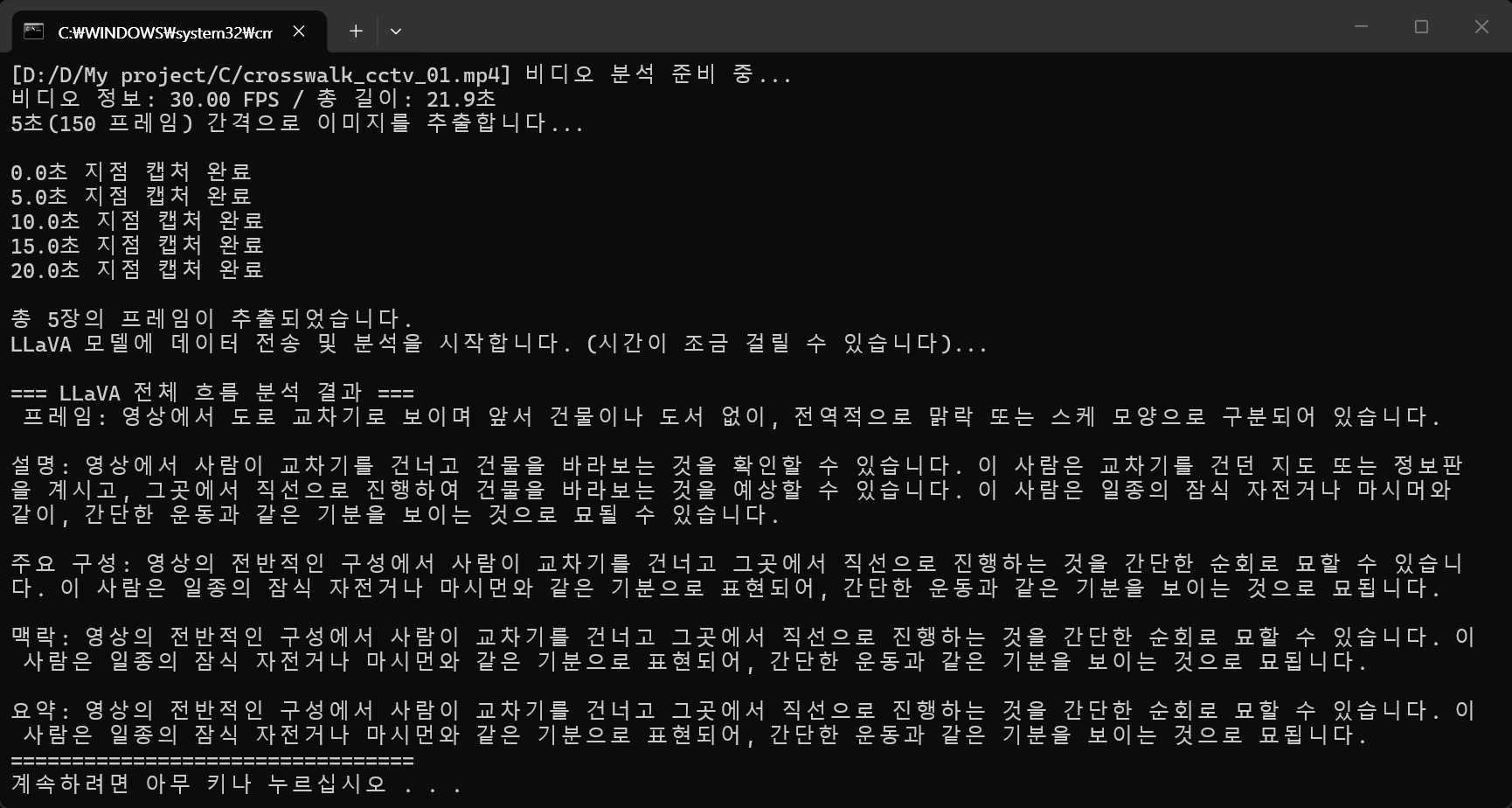
print(f"[{video_path}] 비디오 분석 준비 중...")
# 비디오 파일 열기 및 정보 확인
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print("오류: 비디오 파일을 열 수 없습니다.")
return
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
video_length_sec = total_frames / fps
# 5초에 해당하는 프레임 간격 계산
frame_interval = int(fps * interval_sec)
print(f"비디오 정보: {fps:.2f} FPS / 총 길이: {video_length_sec:.1f}초")
print(f"{interval_sec}초({frame_interval} 프레임) 간격으로 이미지를 추출합니다...\n")
frames_bytes = []
current_frame_pos = 0
# 5초 간격으로 프레임 순회하며 추출
while current_frame_pos < total_frames:
cap.set(cv2.CAP_PROP_POS_FRAMES, current_frame_pos)
ret, frame = cap.read()
if not ret:
break
# 콘솔에 진행 상황 표시
current_time_sec = current_frame_pos / fps
print(f"{current_time_sec:.1f}초 지점 캡처 완료")
# 이미지를 바이트 배열로 변환하여 리스트에 추가
success, buffer = cv2.imencode('.jpg', frame)
if success:
frames_bytes.append(buffer.tobytes())
# 다음 캡처할 프레임 위치로 이동
current_frame_pos += frame_interval
cap.release()
if not frames_bytes:
print("추출된 프레임이 없습니다.")
return
print(f"\n총 {len(frames_bytes)}장의 프레임이 추출되었습니다.")
print("LLaVA 모델에 데이터 전송 및 분석을 시작합니다. (시간이 조금 걸릴 수 있습니다)...\n")
# 여러 장의 이미지를 포함하여 LLaVA에 프롬프트 전송
prompt_text = (
"첨부된 이미지들은 하나의 비디오에서 5초 간격으로 추출된 프레임들이야."
"이미지를 하나 하나 설명하지 말고 이 영상에서 어떤 상황이 벌어지고 있는지 전체적인 흐름과 맥락을 요약해서 설명해줘."
)
try:
response = ollama.chat(
model='llava',
messages=[
{
'role': 'user',
'content': prompt_text,
'images': frames_bytes # 여러 장의 이미지가 담긴 리스트를 통째로 전달
}
]
)
# 최종 결과 출력
print("=== LLaVA 전체 흐름 분석 결과 ===")
print(response['message']['content'])
print("=================================")
except Exception as e:
print(f"Ollama 실행 중 오류 발생: {e}")
if __name__ == "__main__":
video_file = "D:/D/My project/C/crosswalk_cctv_01.mp4" # 테스트할 비디오 파일 경로
# 5초 간격으로 분석 실행
analyze_video_flow(video_file, interval_sec=5)

prompt_text = (
"첨부된 이미지들은 하나의 비디오에서 5초 간격으로 추출된 프레임들이야."
"이미지를 하나 하나 설명하지 말고 이 영상에서 어떤 상황이 벌어지고 있는지"
"전체적인 흐름과 맥락을 요약해서 한글로 설명해줘."
)
※ 참고
3초 간격으로 프레임을 추출하면 8장의 프레임이 모델로 전달되는데, 사용 가능한 context size를 넘었다는 오류가 발생했다.

n_ctx와 n_prompt_tokens는 로컬 LLM을 실행하거나 API 파라미터를 설정할 때 마주치는 핵심 컨텍스트 윈도우(Context Window) 개념입니다
- n_ctx (Context Length): 모델이 한 번에 기억하고 처리할 수 있는 최대 토큰 한도입니다. (예: 4096, 8192, 32768)
- n_prompt_tokens (Prompt Size): 사용자가 입력한 프롬프트(질문, 시스템 지시사항 등)가 차지하는 실제 토큰 크기입니다.
- 동작 원리: 질문이 전송되면 LLM 엔진은 n_ctx 한도 내에서 n_prompt_tokens와 답변 생성에 필요한 토큰을 모두 합산합니다.
만약 질문과 답변(생성 토큰)의 합이 n_ctx 값을 초과하면 에러가 발생하거나 답변이 중간에 잘리게 됩니다.
아래와 같이 num_ctx 옵션을 주거나 프레임 추출 간격 늘리기 등의 방법으로 해결 가능하다.
response = ollama.chat(
model='llava',
messages=[
{
'role': 'user',
'content': prompt_text,
'images': frames_bytes # 여러 장의 이미지가 담긴 리스트를 통째로 전달
}
],
options={
'num_ctx': 8192 # 기본값보다 크게 설정 (컴퓨터 사양에 따라 16384까지도 가능)
}
)
그런데 이미지 해상도 줄이기로는 해결되지 않는다.
# 해상도를 640x360(또는 더 작게)으로 축소
frame = cv2.resize(frame, (640, 360))
# 이미지를 바이트 배열로 변환하여 리스트에 추가
success, buffer = cv2.imencode('.jpg', frame)
if success:
frames_bytes.append(buffer.tobytes())
간단히 생각하기엔 '해상도가 작으면 용량도 작으니 AI가 처리할 데이터도 줄어들겠지?' 싶지만, LLaVA 같은 비전 언어 모델(VLM)은 그렇게 작동하지 않습니다.
왜 해상도를 줄여도 소용이 없을까?
1. 이미지는 픽셀이 아니라 '토큰(Token)'으로 계산됩니다.
LLaVA 모델 내부에는 이미지를 읽어들이는 '비전 인코더(Vision Encoder)'라는 부품이 있습니다. 이 인코더는 이미지가 들어오면 가로세로를 바둑판처럼 잘게 쪼개서 텍스트와 같은 '토큰'으로 변환합니다.
2. 최소 '기본요금(고정 토큰)'이 존재합니다.
이 비전 인코더는 자신이 처리하기 편한 고정된 내부 해상도(예: 336x336)를 가지고 있습니다.
1920x1080 (FHD) 해상도를 넣으면 => 크기를 줄여서 인식합니다.
100x100 (저해상도) 이미지를 넣으면 => 빈 공간을 채우거나 크기를 늘려서 인식합니다.
결과적으로, 1080p 고화질을 넣든 100x100 썸네일을 넣든 AI 입장에서는 이미지 1장당 약 500~1000개의 고정된 토큰을 무조건 소모해 버립니다.
3. 컨텍스트 윈도우(Context Window)가 꽉 참
Ollama의 기본 기억력(Context Window)은 보통 2048개 또는 4096개 토큰입니다. 해상도를 아무리 줄여도 1장당 700개의 토큰을 차지한다면, 단 4~5장만 보내도 메모리 한도에 도달하게 되는 것입니다.
'AI, ML, DL' 카테고리의 다른 글
| [YOLO] YOLO-World (0) | 2026.06.16 |
|---|---|
| [Ollama] Ollama Backend Serve 백엔드 실행 (0) | 2026.06.14 |
| [Ollama] Hugging Face 모델 설치 (Bllossom) (0) | 2026.06.14 |
| [Ollama] Ollama with Python 2 (0) | 2026.06.14 |
| [Ollama] Ollama with Python 1 (0) | 2026.06.13 |